![]()
OCRFeeder is a document layout analysis and optical character recognition application. It is a type of software that leaves much to be desired on the Linux desktop.
OCR software is a companion tool to scanning a document. The scanner software creates a photo-like image of the scanned document. The OCR component lets you edit the text and then export the edited version into a word processor or page-design program.
Linux suffers from critical deficiencies in two types of software: One is income tax preparation, the other is OCR. Whenever I need either of these computing tasks, I close my Linux OS and boot into Microsoft Windows. The OCR tools in that other OS are close to flawless and much easier to use.
That said, if you only do occasional work that requires an editable copy of text from a scanned document, OCRFeeder is one of several Linux packages that gives varying degrees of results. However, you will have to fiddle around with settings and be content to rely on trial and error. OCR in Linux is far from foolproof.
As long as you accept the fact that you will do some heavy cleanup as an alternative to typing the document from scratch, give OCRFeeder a spin. Howerver, it is no match for what is arguably the best Windows-based OCR program, Abbyy Finereader. Abbyy makes an OCR engine for the Linux platform for specialized vertical product makers. Unfortunately, no stand-alone open source version of it is available.
OCR Basics
Joaquim Rocha developed OCRFeeder as a project for his master’s thesis in computer science in 2008. Its latest release is version 0.7.9-1. It takes 33 MB to download and consumes 92MB of disk space once installed.
OCRFeeder automatically outlines a document image’s contents and can distinguish between graphics and text. It attempts to perform OCR over the selected text.
The application exports to four formats. The default option is ODT. The other options are HTML, PDF or plain text.
Key Features
Its chief feature is the GTK+ graphical user interface that allows the user to configure the application for flexible results. It can also be used from the command line for automation.
For example, the GTK graphical user interface lets users correct unrecognized characters. This is a worthwhile convenience over exporting a file into a word processor or text editor for cleanup.
The interface also makes it easy to define or correct bounding boxes, set paragraph styles, import PDFs and save or load a project. Some PDF readers have the ability to save a copy as a text file so it can be edited. Having the ability to import PDF files within OCRFeeder makes this application much more useful.
Significant Downside
On paper, the design specs and built-in features describe a very capable project. The reality is, however, that OCRFeeder does not always give reliable text conversion results.
For example, on some scanned documents, I would have saved considerable time by typing the contents from scratch rather than spending wads of time fixing what was unreadable.
OCRFeeder does have a saving characteristic. On pages that have a mixed design of graphics, text and column formatting, I can work on selected blocks with more accurate conversions and easier manual corrections.
Look and Feel
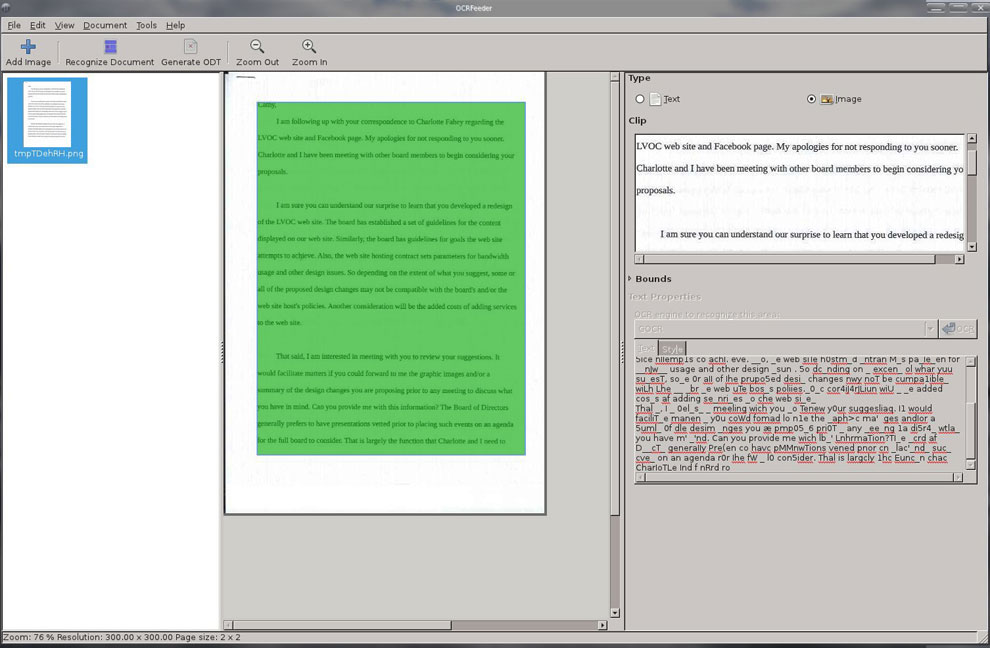
When OCRFeeder first loads, its blank screen resembles a PDF viewer. That similarity remains after you load an existing project file or make a fresh scan. The left side of the app window displays a thumbnail view. The right side of the app window shows a larger view of the document’s content.
The top row holds the traditional menu row. The categories are Save, Edit, view, Document, Tools and Help.
A second row holds several large icons to Add an Image, Recognize Document, Save as ODT and Zoom Out or Zoom In. A third panel splits into top and bottom sections on the right once you highlight a section of text to edit.
The tools for editing are anchored in this right panel. It contains a button for selecting the OCR engine and two buttons to open the text and style controls. These resemble formatting options in a word processor.
Using It
OCRFeeder suffers from a lack of information on how to use it. A quick start guide provided with the installation or included in the Help menu would easily solve this weakness.
Getting a document into OCRFeeder is fairly easy. You can basically use the program to control acquiring an image from an attached scanner, or you can import an existing scanned image. Knowing what to do after the image is on the screen is the application’s make-or-break factor.
For example, you must select the Unpaper function to prepare the scanned image for editing. Then you must click the Recognize Document function to finish the file preparation.
The third step in this process is selecting an OCR engine and then clicking the OCR button to generate an editable display in the editing window. You can read and correct the converted text in this window.
Key Factor
The OCR engine is the secret sauce that makes or breaks OCRFeeder’s success in creating accurate conversion results. OCRFeeder installs with the default OCR engine called Tesseract-ocr. You can add different scanning engines — such as GOCR, OCRAD or Cunieform — from distro repositories and Synaptic Package Manager.
Once you download an additional OCR engine, use the Tools-OCR Engines-Add menu option to include it in OCRFeeder. I found that different OCR engines produce better results depending on the type of document and the amount of text involved. Sometimes you get better results by working on larger text blocks in smaller segments.
Other issues also affect the accuracy of the text translation. For instance, the font and point size makes a big difference. Manipulate the text when possible to plain fonts and larger points.
Bottom Line
OCRFeeder is no better than other Linux-based OCR applications I have used. They all suffer from less-than-optimum OCR translation engines.
Expect worse results when starting out. As you gain familiarity with the settings, you will learn how to use OCRFeeder more effectively.